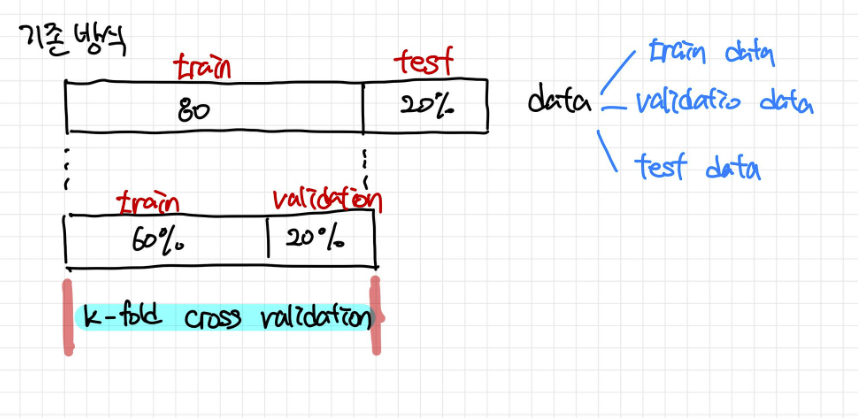
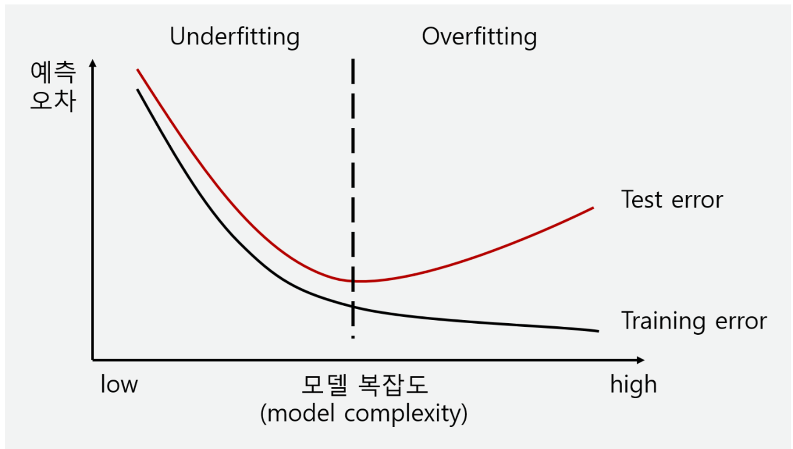
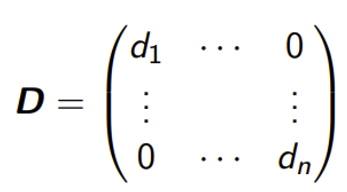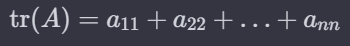cf) 데이터 train data : 학습을 통해 가중치, 편향 업데이트 validation data : 하이퍼파라미터 조정, 모델의 성능 확인 test data : 모델의 최종 테스트 하이퍼파라미터 : 값에 따라서 모델의 성능에 영향을 주는 매개변수들(ex. learning rate, 은닉층의 수, 뉴런의 수 등) ↔ 가중치, 편향은 학습을 통해 바뀌어져가는 변수이다. cf) 기존 방식 1. 교차검증(cross-validation) 같은 데이터를 여러 번 반복해서 나누고 여러 모델을 학습하여 성능을 평가하는 방법 데이터를 학습용/평가용 데이터 세트로 여러 번 나눈 것의 평균적인 성능을 계산하면, 한 번 나누어서 학습하는 것에 비해 일반화된 성능을 얻을 수 있기 때문 (조금 더 안정적인 성능이 나옴) 장..