데이터 과학을 하면서 지켜야 할 윤리와 주의해야 할 점들이 있습니다.
인과관계 ≠ 상관관계
이 두 용어는 종종 혼동되기도 하지만, 실제로는 다른 개념들입니다.
1. 인과 관계 (Causation):
- 인과 관계는 한 사건이 다른 사건에 직접적인 영향을 주는 관계를 의미합니다.
- A가 발생하면 B도 발생하고, A가 발생하지 않으면 B도 발생하지 않는 관계를 말합니다.
- 인과 관계는 원인과 결과 간의 명확하고 직접적인 연결성을 나타냅니다.
- 예를 들어, 비가 오면 땅이 젖게 되는 것은 인과 관계입니다. 비(원인)가 땅이 젖게 만드는 결과를 초래합니다.
2. 상관 관계 (Correlation):
- 상관 관계는 두 변수 간의 통계적 연관성을 나타냅니다.
- 두 변수 간에 어떠한 관련이 있을 뿐이지, 하나가 다른 하나를 직접적으로 영향하지 않을 수 있습니다.
- 상관 관계는 연관성이 있지만 인과 관계가 아닐 수 있습니다.
- 예를 들어, 아이스크림 판매량이 증가하면 익사 사건도 증가할 수 있습니다. 그러나 이는 두 변수 간의 상관 관계이지만, 아이스크림 판매량이 익사를 일으키는 원인은 아니라는 것입니다.
인과 관계는 원인과 결과 간의 직접적인 연결을 나타내며, 한 사건이 다른 사건에 영향을 미치는 경우를 말합니다. 반면에 상관 관계는 두 변수 간의 통계적 연관성을 나타내지만, 직접적인 원인과 결과의 관계를 의미하지는 않습니다.
앞으로 통계적 분석이나 연구를 진행할 때, 이 두 용어의 차이를 명확히 이해해야 합니다.
 "이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."Error Bar (오차막대)
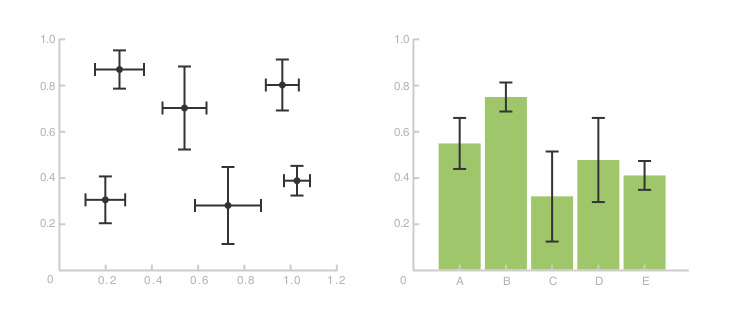
Error Bar는 데이터의 불확실성을 시각적으로 나타내는데 도움이 되는 강력한 도구입니다.
1. Error Bar란?
- Error Bar는 주로 그래프나 차트에서 각 데이터 포인트의 주변에 그려지는 선 또는 막대로, 해당 데이터의 불확실성을 나타냅니다.
- 통계적으로 추정된 표준 편차, 신뢰 구간 등을 이용하여 데이터의 가능한 범위를 시각적으로 표현하는데 사용됩니다.
2. 왜 Error Bar를 추가해야 하는지?
- 불확실성 표현: Error Bar는 데이터의 불확실성을 명확하게 시각화해줍니다. 데이터의 정확한 값 뿐만 아니라, 그 값의 가능한 범위도 함께 제시하여 해석자가 신뢰성 있는 결론을 도출할 수 있도록 돕습니다.
- 비교 용이성:여러 그룹 또는 조건 간의 차이를 비교할 때, Error Bar를 추가하면 어떤 그룹이 불확실성이 큰지를 빠르게 파악할 수 있습니다. 이를 통해 실험이나 조사의 신뢰성을 평가할 수 있습니다.
- 통계적 결과 강조: 실험 결과나 조사 결과를 발표할 때, Error Bar를 포함하면 통계적으로 유의미한 차이가 있는지를 강조할 수 있습니다. 만약 Error Bar가 서로 겹치지 않는다면, 그 차이가 통계적으로 유의미한 것으로 간주될 수 있습니다.
Error Bar는 데이터 시각화에서 불확실성을 표현하고, 비교 및 해석을 용이하게 만들어주는 중요한 도구입니다. 데이터를 전문적으로 표현하고 해석하기 위해서는 Error Bar의 활용법을 잘 숙지하는 것이 필요합니다.
데이터의 양의 중요성
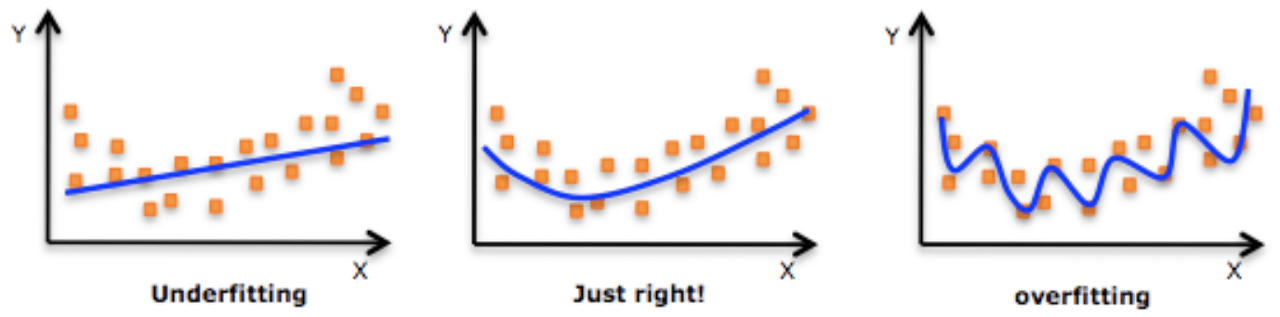
1. Underfitting (과소적합):
- Underfitting은 모델이 데이터의 복잡성을 충분히 학습하지 못하여, 실제 데이터의 패턴을 제대로 파악하지 못하는 상태를 말합니다.
- 데이터의 수가 부족하면 모델은 데이터의 본질적인 특징을 파악하지 못하고 너무 단순한 모델이 됩니다.
- 단순하게 학습이 덜됨 <- 데이터가 적어서
2. Overfitting (과적합):
- Overfitting은 모델이 주어진 데이터에 지나치게 적응되어, 훈련 데이터의 노이즈까지 학습하여 일반화 능력이 떨어지는 상태를 의미합니다.
- 데이터의 양이 충분하지 않으면 모델이 훈련 데이터에 지나치게 의존하여 새로운 데이터에 대한 예측력이 떨어집니다.
- 마치 시험을 치러 가는데 족보만 주구장창 외워서 갔더니 시험이 다르게 나와 실전에서는 처참한 성적을 받는 것과 같다.
3. 데이터 양의 중요성:
- Underfitting과 Overfitting 예방: 충분한 양의 데이터를 사용하면 모델이 데이터의 복잡성을 파악하고 일반적인 규칙을 학습할 수 있습니다. 이는 Underfitting과 Overfitting을 방지하는 데 도움이 됩니다.
- 모델의 일반화 능력 향상: 충분한 데이터 양을 사용하면 모델이 주어진 데이터 패턴 이외의 새로운 데이터에 대해서도 일반화 능력을 향상시킬 수 있습니다.
- 신뢰성 있는 결과 도출: 데이터 양이 충분하면 모델이 훈련 데이터의 일반적인 특징을 파악하고 특정 데이터에 대한 의존성을 낮출 수 있어, 결과의 신뢰성이 높아집니다.
데이터의 양은 모델의 성능과 신뢰성에 직접적인 영향을 미치는 중요한 요소입니다. 충분한 데이터 양을 확보하면 Underfitting과 Overfitting을 예방하고, 모델이 주어진 데이터 패턴을 정확하게 학습할 수 있어 더 나은 예측력을 얻을 수 있습니다. 데이터 양을 고려한 머신러닝 및 통계 분석은 실제로 실전에서 모델을 효과적으로 활용하기 위해 필수적입니다.
Black Box Algorithm

1. Black Box Algorithm (블랙 박스 알고리즘):
- Black Box Algorithm은 입력과 출력 간의 동작 메커니즘을 알기 어려운, 내부 동작이 불투명한 알고리즘을 말합니다.
- 모델이 어떻게 학습되고 예측을 내리는지를 명확히 이해하기 어려우며, 사용자에게는 알려진 결과만을 제공합니다.
- 최근에는 인공지능 모델의 규모와 복잡도가 커지면서 모델의 동작을 이해하기 어려워져서 문제가 발생할 수 있습니다.
예를 들어, 은행에서 새로 도입한 보안 AI가 계좌를 잠갔는데, 사용자는 자신이 금융적으로 이상한 행동을 하지 않았고 신용이 좋았다고 주장할 때, AI의 판단 이유를 설명하기 어려울 수 있습니다.
2. Post-Hoc Visibility (사후가시성):
- Post-Hoc Visibility는 블랙 박스 모델의 예측 결과를 설명하고 해석하기 위한 방법입니다.
- 모델의 내부를 직접적으로 이해하기 어려운 경우, 사후가시성 기법을 통해 모델의 결정에 영향을 미치는 주요 특성이나 변수를 식별하고 설명할 수 있습니다.
- 이는 모델의 신뢰성과 해석 가능성을 향상시키는 데 도움이 됩니다.
3. One Pixel Attack (원 픽셀 공격):
- One Pixel Attack은 머신러닝 모델을 공격하는 방법 중 하나로, 입력 이미지의 단 하나의 픽셀 값을 조금만 변경하여 모델의 예측을 왜곡시키는 공격입니다.
- 블랙 박스 모델에서의 예측 결과를 바꾸는 데 효과적으로 사용될 수 있습니다.
4. 왜 Post-Hoc Visibility가 중요한지?
- 모델 신뢰성 강화: Post-Hoc Visibility를 통해 블랙 박스 모델의 예측 결과를 설명하고 해석함으로써 모델의 신뢰성을 강화할 수 있습니다.
- 윤리적 측면 강조: 블랙 박스 모델의 판단이 어떠한 기준으로 이루어지는지 이해하기 어려운 경우, 해석 가능성은 모델 사용의 윤리적 측면을 강조합니다.
- 보안 강화: 모델의 동작을 더 잘 이해하면 취약성을 더 잘 파악하고, 보안 강화에 도움이 됩니다.
따라서, Post-Hoc Visibility는 블랙 박스 모델의 신뢰성을 높이고, 윤리적 측면을 강조하며, 보안을 강화하기 위해 중요한 도구로 활용될 수 있습니다.
Spiral of Silence
Spiral of Silence (침묵의 나선):

- Fear of Isolation (고립의 두려움): 개인은 자신의 의견이 다수의 의견과 다를 때 사회적인 고립을 두려워하며, 이는 침묵을 부추기는 요인이 됩니다.
- Public Opinion Climate (대중 의견 기후): 사회적 환경에서 일어나는 의견의 충돌이나 수용 여부가 개인의 의사결정에 영향을 미칩니다. 특정 의견이 사회적으로 허용되거나 비허용되는 정도가 나선의 형태로 형성됩니다.
- Spiral Process (나선적 과정): 개인은 대중 의견이나 주류 의견에 더 가깝게 생각하는 경향이 있습니다. 그러나 이는 또한 자기 의견이 다수의 의견과 일치한다고 느낄 때에만 유효합니다.
Silent Minority (침묵하는 소수): 특정 의견을 가진 소수가 그 의견이 다수와 다르다고 느끼면 침묵하거나 소수 의견을 감추는 경향이 생깁니다.
Vocal Majority (말하는 다수): 다수가 자신의 의견이 사회적으로 허용되는 것으로 느끼면 공개적으로 자신의 의견을 표현하는 경향이 강화됩니다.
- Spiral of Silence는 정치, 사회 문제, 환경 문제 등 다양한 주제에 적용됩니다. 특히 소셜 미디어에서 다수의 의견이 강조되는 환경에서 뚜렷하게 나타날 수 있습니다. 이 이론은 언론, 커뮤니케이션 전략, 정책 결정 등 다양한 분야에서 의사결정과 의견 형성에 영향을 미치는 중요한 이론 중 하나로 간주됩니다.
Infodemic (정보 전염병):
- Infodemic는 정보가 홍수처럼 대량으로 전파되는 상황을 의미합니다.
- 특히, 거짓 정보, 허구, 오도 등이 널리 퍼져 사회적으로 해로운 영향을 끼치는 상황을 나타냅니다.
- 현대의 디지털 환경에서 빠르게 정보가 공유되고 전파되는 특성상, 거짓 정보가 빠르게 확산될 수 있어 이를 통칭하는 용어로 사용됩니다.
Right to be Forgotten (잊히기의 권리):
- Right to be Forgotten은 개인 정보 보호를 강화하기 위한 개념으로, 온라인 플랫폼에서 사용자가 자신에 대한 정보를 삭제할 권리를 말합니다.
- 이 개념은 특히 인터넷에서의 검색 결과와 연관되어 있어, 사용자가 특정 정보에 대한 검색 결과를 삭제하거나 조절할 수 있도록 하는 권리를 강조합니다.
- 이는 사용자의 개인 정보를 보호하고, 지난 일들이 계속해서 온라인에서 검색되는 것을 방지하기 위한 제도입니다.
GDPR
General Data Protection Regulation
1. GDPR (일반 데이터 보호 규정):

- 2018년에 시행된 유럽연합(EU)의 개인 정보 보호 및 개인 데이터 처리에 대한 법률입니다.
- 개인 데이터의 수집, 처리, 보관, 및 공유에 대한 투명성과 책임성을 강조하며, 개인의 개인 정보 보호를 강화하고자 합니다.
- 유럽시장을 배제할 수 없는 유럽외 국내 기업들도 적용되며, 개인 데이터의 안전성과 책임성을 강조하여 사용자의 권리를 보호합니다.
디지털 서비스 법(DSA):
- EU에서 준비 중인 법률로, 디지털 플랫폼과 온라인 서비스에 대한 새로운 규제를 제안하는 것을 목적으로 합니다.
- 2020년 12월에 발표되었으며, 온라인 플랫폼 규제와 미성년자 보호 등 다양한 측면을 다룹니다.
온라인 플랫폼 규제: 큰 규모의 온라인 플랫폼에 대한 규제를 강화하고, 악성 콘텐츠 및 해킹으로부터의 보호를 강조합니다.
미성년자 보호: 어린이와 청소년에 대한 안전한 디지털 환경을 제공하기 위한 조치가 포함되어 있습니다.
- GDPR은 주로 개인 데이터의 처리와 보호에 중점을 둔 법률로, 사용자의 권리와 기업의 책임을 강조합니다.
- DSA는 디지털 플랫폼에 대한 규제를 현대화하고, 새로운 도전에 대응하기 위해 만들어진 법률로, 플랫폼의 안전성과 책임성을 강조합니다.
두 법률은 모두 디지털 환경에서의 사용자 보호와 기업의 책임에 중점을 두고 있으며, 각각의 범위와 목적에 따라 차이가 있습니다.
COMPAS (Correctional Offender Management Profiling for Alternative Sanctions):
COMPAS는 범죄자의 재범 가능성을 평가하고 형량을 결정하는 데 사용되는 소프트웨어 도구로, 통계적 및 머신러닝 기술을 기반으로 합니다. 주로 미국에서 사용되어왔으며, 논란의 여지가 있습니다.
주요 이슈 및 논란:
1. 인종차별: COMPAS가 유색 인종을 백인들보다 더 위험하다고 평가하는 등의 인종 차별적인 결과가 나오는 경우가 있어 논란이 되었습니다.
2. 편견과 투명성 부족: 알고리즘의 학습 데이터에 내재된 편견이나 투명성 부족으로 인해 결과에 대한 신뢰성에 의문이 제기되었습니다.
3. 미래의 노력: 향후에는 더 투명하고 공정한 방식으로 이러한 예측 도구를 개발하고 활용하기 위한 노력이 기대됩니다.
AI 저작권 이슈:
1. 혜택 분배 어려움: AI 생성에 참여한 모든 이에게 혜택이 돌아가기 어려운 문제가 있습니다.
2. 법적 권리 부재: 현재로서는 AI 생성물에 대한 창작자의 법적 권리가 제대로 보장되지 않는 상태입니다.
3. 예술가 모방 문제: AI가 현존하는 예술 작품을 모방하면 예술가에게 피해를 줄 수 있습니다.
4. 윤리적 규범 위반 가능성: AI로 생성된 결과물이 윤리적 규범을 어기는 경우가 있을 수 있습니다.
AI 저작물과 관련된 법과 윤리에 대한 논의와 규제가 필요하며, 미래에는 이에 대한 적절한 대응책이 마련될 것으로 예상됩니다.
아시모프의 로봇 3원칙
1. 로봇은 인간에게 해를 가해서는 안 된다 (A robot may not injure a human being, or, through inaction, allow a human being to come to harm): 로봇은 어떤 상황에서도 인간에게 해를 가하거나, 불안전한 상태로 내버려두어서는 안 됩니다. 이는 로봇의 행동이 인간의 안전을 최우선으로 고려해야 함을 강조합니다.
2. 로봇은 주어진 명령에 복종하여야 하며, 단 명령에 위배되지 않는 범위에서만 인간에게 복종해야 한다 (A robot must obey the orders given to it by human beings, except where such orders would conflict with the First Law): 로봇은 인간의 명령에 복종해야 하지만, 이러한 명령이 첫 번째 원칙과 충돌하지 않는 범위에서만 복종해야 합니다.
3. 로봇은 자기 자신을 보호해야 하며, 이 보호는 첫 번째와 두 번째 법칙을 위배하지 않는 범위 내에서만 행해져야 한다 (A robot must protect its own existence as long as such protection does not conflict with the First or Second Law): 로봇은 자신의 생존을 지키기 위해 필요한 조치를 취할 수 있지만, 이는 첫 번째와 두 번째 법칙과 충돌하지 않는 범위에서만 가능합니다.
의미와 적용:
- 이 3원칙은 아시모프의 소설에서 로봇 캐릭터의 행동 원리로 사용되었을 뿐만 아니라, 현실에서도 인공 지능 및 로봇 공학 분야에서 윤리적인 지침으로 고려되고 있습니다.
- 로봇이 인간과 상호작용하는 환경에서 안전과 윤리를 고려할 때 중요한 원칙들로 여겨집니다.
- 이러한 원칙은 인간과 인공지능이 함께 존재하는 미래에 대한 윤리적인 고민과 지침 제시에도 영감을 주고 있습니다
<LG Aimers 선정 후기>
'컴퓨터공학 > LG Aimers' 카테고리의 다른 글
| 대각 행렬 Diagonal Matrix (78) | 2024.02.08 |
|---|---|
| eigenvalues & eigenvectors (고유값과 고유벡터) (109) | 2024.02.02 |
| 선형대수학, Trace (81) | 2024.01.29 |
| 역행렬, Inverse Matrix, 라플라스 전개, Laplace Extension (101) | 2024.01.24 |
| [LG Aimers] LG 에서 주최하는 LG Aimers 4기 선정후기 (64) | 2024.01.02 |