반응형
오버피팅(overfitting)이란?
- 학습 데이터에 대해 과하게 학습하여 실제 데이터에 대한 오차가 증가하는 현상
- train-set에서는 정확도 매우 높게 나옴, but test-set에서는 낮은 정확도
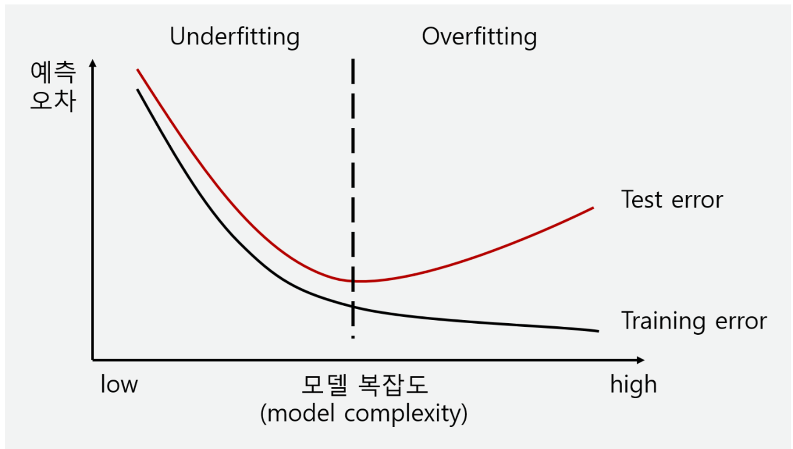
오버피팅이 발생하는 이유
- 훈련 데이터의 부족
- 적은 양의 훈련 데이터로 모델을 훈련시키면, 모델은 훈련 데이터에만 맞추기 쉬움
- 복잡한 모델 구조
- 모델이 지나치게 복잡하면 훈련 데이터에 대한 노이즈나 특정 패턴을 학습하게 되어 일반화 성능이 감소
- 과도한 훈련
- 훈련 데이터에 모델을 지나치게 많이 학습시키면 특정 데이터에 과적합될 가능성이 높아짐
해결 방안
- 더 많은 데이터 수집
- 더 많은 데이터를 수집함으로써 다양한 상황에서도 일반화 되도록 함
- 데이터 확장
- 기존 데이터를 변형하여 새로운 데이터를 생성함으로써 훈련 데이터의 양을 늘림
- 모델 단순화(복잡도를 줄임)
- 동일한 데이터에 대해 모델의 복잡도를 줄이면 데이터로부터 일반적인 패턴을 학습해 일반화
- ⇒ Generalization(일반화)
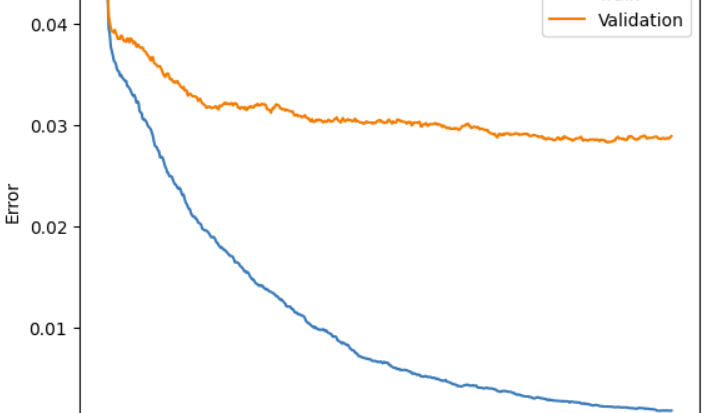

ex)
시험공부를 하면 나 자신(model)이 그 과목에 관련된 문제를 주어지면 잘 푸는 학생이 되어야 고득점을 할 수 있다
좋은 선배님께서 작년 족보(train data)를 주셨다 하자
족보를 가지고 공부하면 다른 학생들 보다 더 효율적으로 나의 시험 문제 대비 능력은 오를 것이다 (train error 감소)
그러나 족보만 너무 많이 학습하고 다른 자료를 공부 안하면
진짜 시험(valiation data) 때 족보에 없는 문제가 나오면 머리가 하얘지고 못 풀것이다 (validation error 감소하지 않음)
이 현상을 나 자신이 족보에 Overfitting 되었다 볼 수 있다
이를 방지 하기 위해서는
문제를 많이 풀거나->학습 데이터의 양을 늘리기
문제 없으면 친구랑 서로 질문 만들기->학습 데이터 합성해서 만들기
좋은 문제를 풀고->질좋은 데이터 만들기
족보를 적당히 참고->학습을 overfitting되기 전에 멈춘다
할 수 있다
반응형
'컴퓨터공학 > LG Aimers' 카테고리의 다른 글
| k-fold cross-validation 교차 검증 (언더핏팅 방지) (71) | 2024.03.07 |
|---|---|
| [LG Aimers] 해카톤 후기, 코드 분석 (82) | 2024.03.06 |
| 대각 행렬 Diagonal Matrix (78) | 2024.02.08 |
| eigenvalues & eigenvectors (고유값과 고유벡터) (109) | 2024.02.02 |
| 선형대수학, Trace (81) | 2024.01.29 |