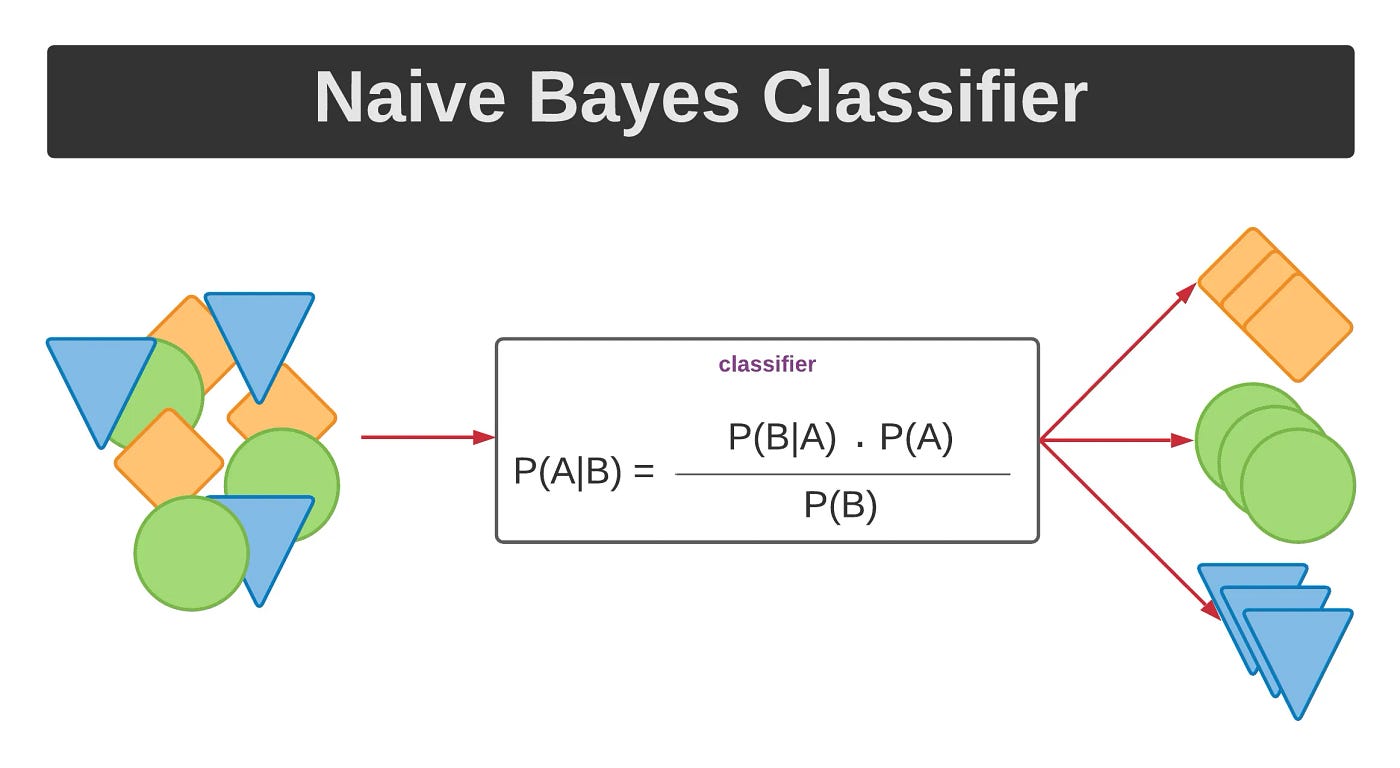
네이브 베이즈는 베이즈 정리에 기반한 간단하지만 효과적인 확률론적 분류기의 집합이다."네이브(Naive)"라는 이름은 각 특성(또는 예측 변수)들이 클래스 레이블에 대해 서로 독립적이라고(independent) 가정하기 때문에 붙여졌다. 실제로 미국에서는나이브라고 발음한다단순한 사람보고 Don't be so Naive!이런식으로 사용된다 Independent 하다는 이 가정은 실제 데이터에서는 자 만족되지 않지만 계산을 크게 단순화시켜 준다.Bayes' Theorem 베이즈 이론P(C|X) = P(X|C)P(C) / P(X) 여기서:P(C|X)는 특성 X가 주어졌을 때 클래스 C의 사후 확률이다.P(X|C)는 클래스 C가 주어졌을 때 특성 X를 관측할 가능성인 값으로, 훈련 데이터 (Train Set..