결측 값은 AI 개발자들에게 매우 큰 골칫 거리이다
전처리의 기본 단계이며
결측 값들을 채우는 방법은 매우 많다
가능한 다른 Feature들과 관계를 찾아서 채우면 좋겠지만
불가능하거나 너무 복잡한 경우가 있다
단순하게 채우는 가장 간단한 방법은
1. 최빈값
2. 평균값
3. 중앙값
.. 등등 있다
이 과정을 한번에 해주는 library가 Scikit-learn의 imputer 라이브러리다
코드 예시를 한번 보자
MissingIndicator
from sklearn.impute import MissingIndicator
import numpy as np
# Example data with missing values
X = np.array([[1, 2, np.nan],
[np.nan, 3, 4],
[5, np.nan, 6]])
# Create a MissingIndicator object
indicator = MissingIndicator()
# Fit the indicator to the data and transform the data
indicator.fit_transform(X)
# Output the indicator matrix
print(indicator.features_)
print(indicator.transform(X))
Missing Indicator은 결측값이 있는지! 없는지! 의 유무를 (binary Classifier) 1과 0으로 채워준다
보통 결측값은 nan, null 로 표시되어있는데 1 과 0으로 표시해준다
# Create a MissingIndicator object
indicator = MissingIndicator()
MissingIndicator object을 만들어주고
# Fit the indicator to the data and transform the data
indicator.fit_transform(X)
fitting 과 transform을 한번에 하면 된다!
SimpleImputer
from sklearn.impute import SimpleImputer
import numpy as np
# Example dataset with missing values
X = np.array([[1, 2], [np.nan, 3], [7, 6]])
# Create an instance of SimpleImputer with strategy='mean'
imputer = SimpleImputer(strategy='mean')
# Fit the imputer on the data (calculate the mean for each feature)
imputer.fit(X)
# Transform the dataset by replacing missing values with the mean
X_imputed = imputer.transform(X)
print("Original data:")
print(X)
print("\\nImputed data:")
print(X_imputed)
위에 보면 간단한 3x2 데이터 셋을 만들어 뒀다
# Create an instance of SimpleImputer with strategy='mean'
imputer = SimpleImputer(strategy='mean')
mean, 평균값으로 채우는 알고리즘을 채택해 SimpleImputer 를 정의 해준다
# Fit the imputer on the data (calculate the mean for each feature)
imputer.fit(X)
# Transform the dataset by replacing missing values with the mean
X_imputed = imputer.transform(X)
데이터에 fitting을 해주고 transform을 해주면 평균값으로 결측 값들이 처리된다!
KNNImputer
from sklearn.impute import KNNImputer
import numpy as np
# Example data with missing values
X = np.array([[1, 2, np.nan],
[3, np.nan, 5],
[np.nan, 6, 7]])
# Initialize KNNImputer
imputer = KNNImputer(n_neighbors=2) # Using 2 nearest neighbors for imputation
# Impute missing values
X_imputed = imputer.fit_transform(X)
print("Original data:")
print(X)
print("\nImputed data:")
print(X_imputed)
KNN - K nearest neighbor
https://tonnykang.tistory.com/216
k-Nearest Neighbors (k-NN) 모델 KNN
k-NN(k-Nearest Neighbors)는 지연 학습 알고리즘이다.정의k-NN은 함수가 Locally (가깝게) 근사되고, 모든 계산이 함수 평가 시점까지 미뤄지는 지연 학습 알고리즘이다. 분류와 회귀 모두에서 알고리즘은
tonnykang.tistory.com

1. Euclidiean Distance: 점의 직선거리와 같다
2. Manhattan Distance: L1 norm
3. Chebyshev Distance: 벡터의 성분중 절대값이 가장 큰 값을 거리로 가진다
4. Minkowski Distance: norm을 일반화 한 함수
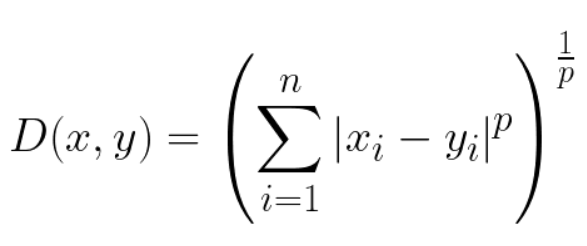
p=inf -> Chebyshev Distance
p=1-> Euclidian Distance
p=2-> Manhattan Distance
from sklearn.impute import KNNImputer
# Initialize KNNImputer with a specific distance metric
imputer = KNNImputer(n_neighbors=2, metric='euclidean')
# Impute missing values
X_imputed = imputer.fit_transform(X)
metric이라는 파라미터를 통해 explicit하게 거리 계산을 해줄 수 있다
기본 default는 euclidiean이다
한 column의 결측값을 채우는데 거리를 계산하는데 모든 column이 다 이용되면
다른 column들에 결측값이 있어도 상관은 없다
그러나 column의 값들이 범주형 (문자열) 데이터면 문제가 생길 수 있다
https://tonnykang.tistory.com/165
K-fold Cross Validation 심화편 (Data Leakage, Stratified)
https://tonnykang.tistory.com/137 k-fold cross-validation 교차 검증 (오버피팅 방지) cf) 데이터train data : 학습을 통해 가중치, 편향 업데이트validation data : 하이퍼파라미터 조정, 모델의 성능 확인test data : 모델
tonnykang.tistory.com
'컴퓨터공학 > 인공지능' 카테고리의 다른 글
| 딥러닝과 뉴런, 파이썬 케라스 코드 (83) | 2024.07.29 |
|---|---|
| 파이선 pandas 라이브러리 get_dummies() (64) | 2024.05.28 |
| Naive Bayes model, 네이브 베이즈 모델 (75) | 2024.05.27 |
| k-Nearest Neighbors (k-NN) 모델 KNN (69) | 2024.05.26 |
| K-fold Cross Validation 심화편 (Data Leakage, Stratified) (56) | 2024.04.04 |