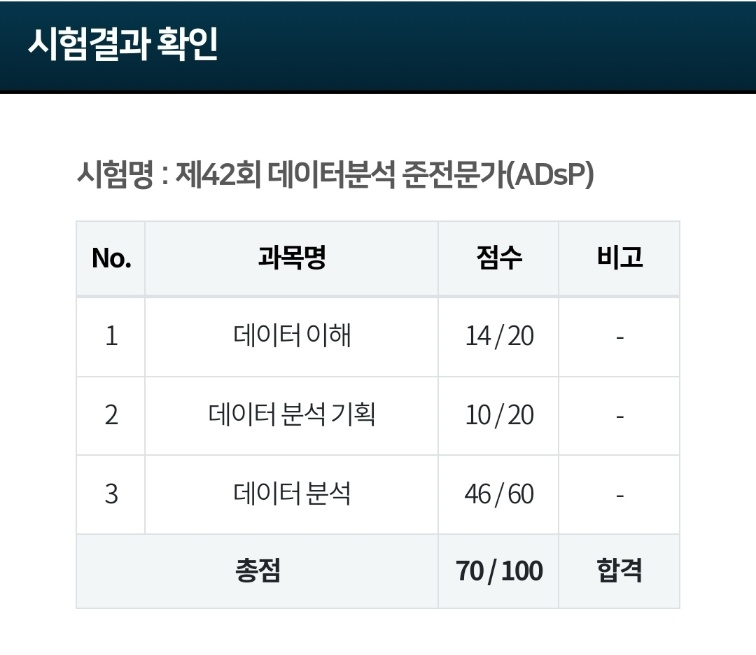
밑으로 내려가시면 독한한 방법과 시험 후기가 있습니다!ADsP 데이터분석 준전문가 자격증 데이터 분석 분야에서 유일한 국가공인 자격증인 ADsP(Advanced Data Analytics Semi-Professional)는 데이터 초보자들이 빠르게 접근할 수 있는 좋은 자격증입니다.ADsP에 대해 알아보려는 분들은 같은 분야의 ADP(데이터분석 전문가)와 헷갈릴 수 있지만, 이 두 자격증은 난이도와 시험 과목에서 큰 차이를 보입니다.ADsP vs ADP: 자격증 비교구분ADP(데이터분석 전문가)ADsP(데이터분석 준전문가)시험 과목 수5과목3과목데이터 이해OO데이터 처리 기술 이해OX데이터 분석 기획OO데이터 분석OO데이터 시각화OXADP는 서술형 문제도 포함되어 있고, 시험 과목이 5과목으로 ADs..