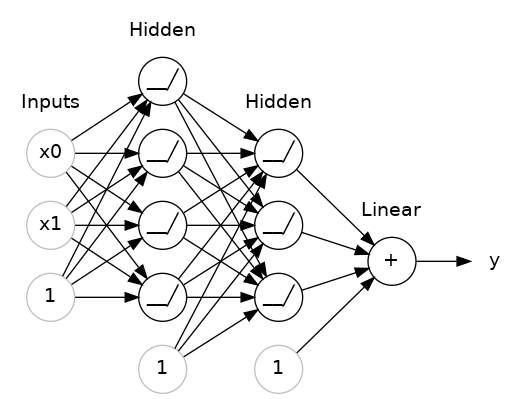
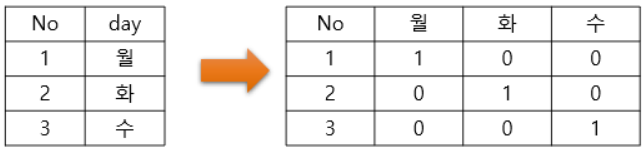
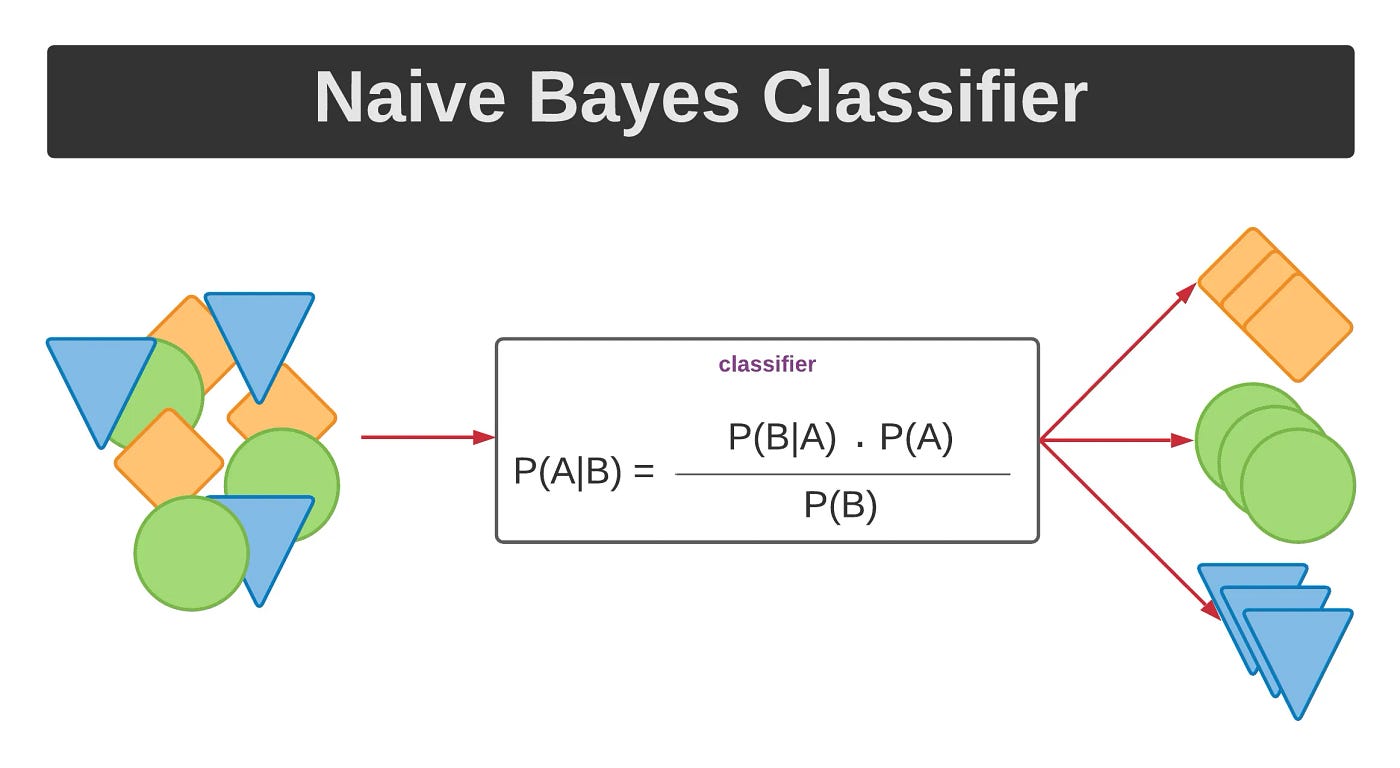
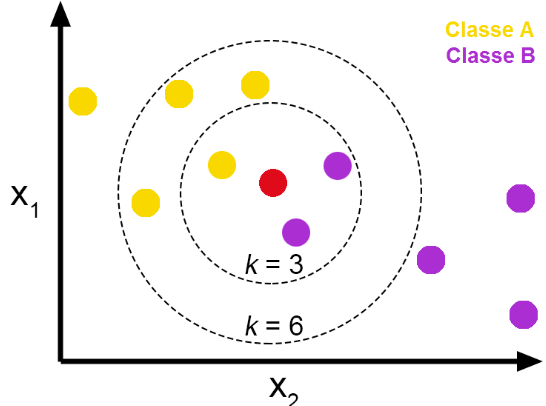
학습 곡선 해석하기훈련 데이터에 있는 정보를 크게 두 가지로 나눌 수 있습니다: 신호(signal)와 노이즈(noise)입니다. 신호는 모델이 새로운 데이터에서 예측할 때 도움이 되는 부분이며, 일반화될 수 있는 정보입니다. 반면, 노이즈는 훈련 데이터에서만 나타나는 우연한 변동이나 의미 없는 패턴을 포함하고 있으며, 실제로는 예측에 도움이 되지 않는 정보입니다.모델을 훈련할 때, 우리는 훈련 세트의 손실(loss)을 최소화하는 가중치 또는 파라미터를 선택합니다. 그러나 모델의 성능을 정확하게 평가하려면 새로운 데이터 세트, 즉 검증 데이터(validation data)에서 평가해야 합니다.훈련할 때, 우리는 각 에포크마다 훈련 세트의 손실을 그래프로 그립니다. 여기에 검증 데이터의 손실도 추가로 플로팅..