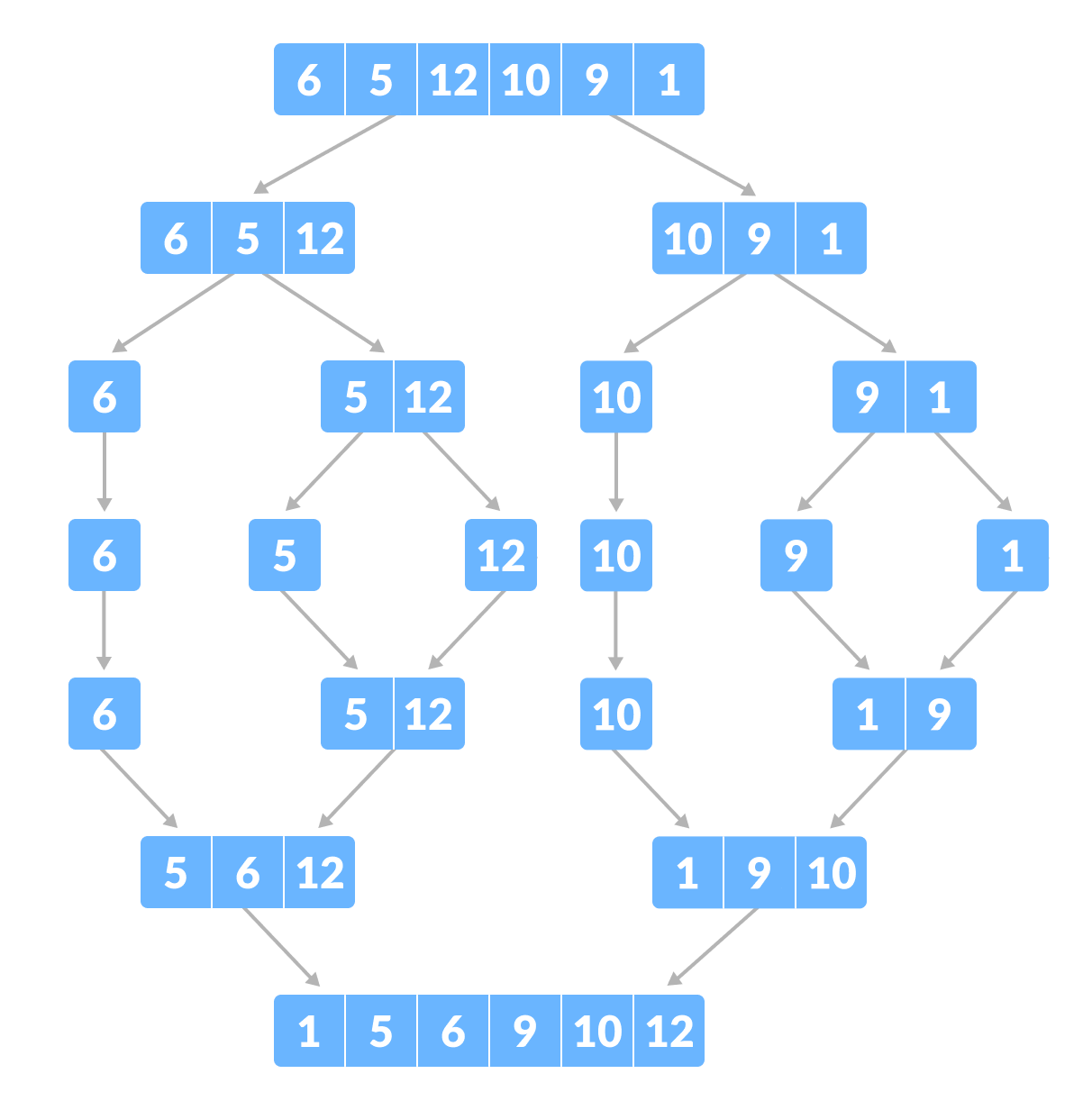
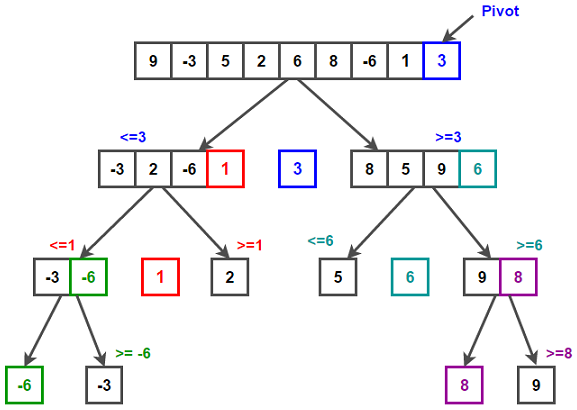
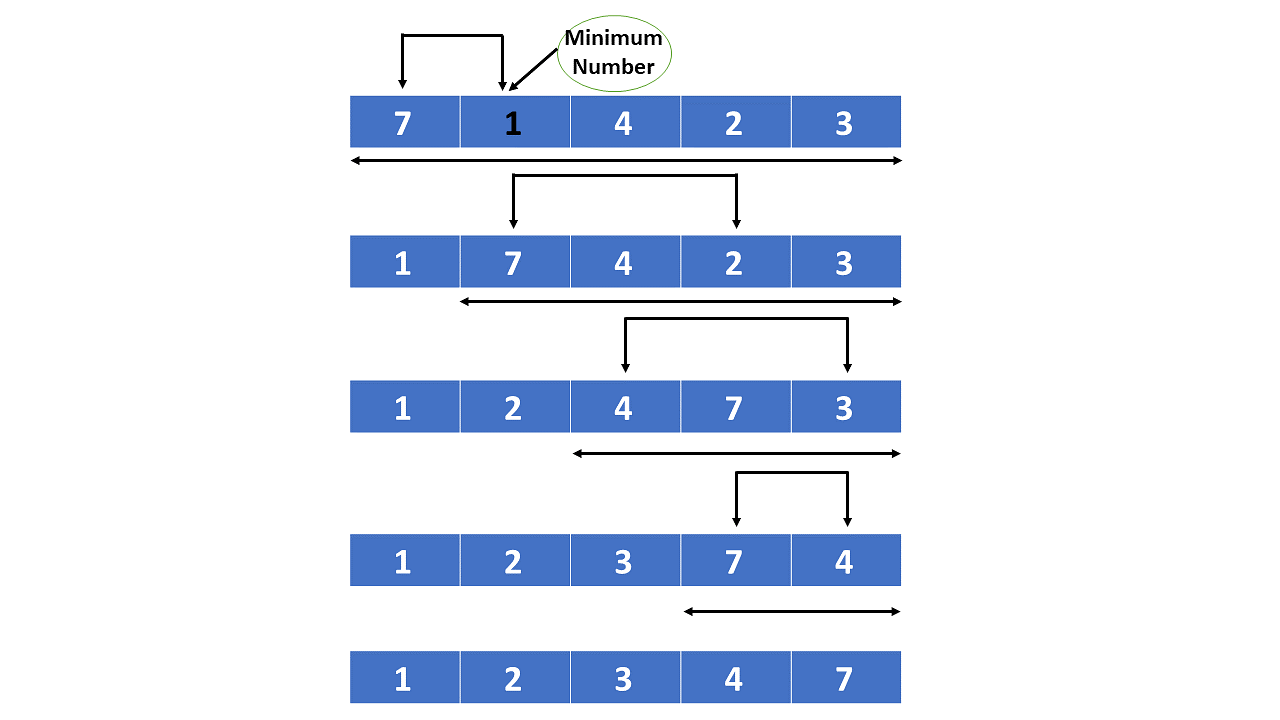
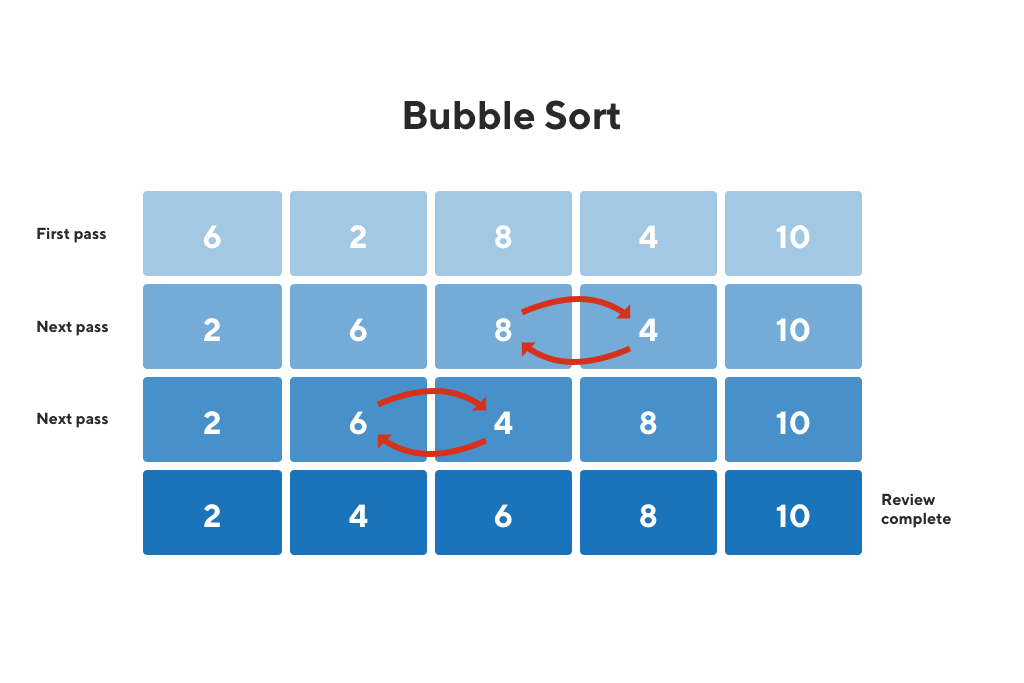
효율적인 정렬을 위한 강력한 무기, 합병 정렬 프로그래밍 분야에서 정렬 알고리즘은 매우 중요한 위치를 차지합니다. 데이터를 특정 순서로 정렬하는 것은 다양한 문제를 해결하는 데 필수적입니다. 이러한 정렬 알고리즘 중 하나인 머지 소트(Merge Sort)는 분할 정복(Divide and Conquer) 기법을 활용하여 효율적이고 안정적인 정렬을 수행합니다. 작동 원리 살펴보기 머지 소트는 다음과 같은 세 단계로 진행됩니다. 1. 분할(Divide) 먼저, 정렬해야 할 배열을 두 개의 서브 배열로 나눕니다. 이 과정을 재귀적으로 반복하여 배열의 크기가 1이 될 때까지 계속 분할합니다. 배열의 크기가 1이 되면 더 이상 나눌 수 없으므로, 이를 기저 조건(base case)으로 합니다. 2. 정복(Conqu..