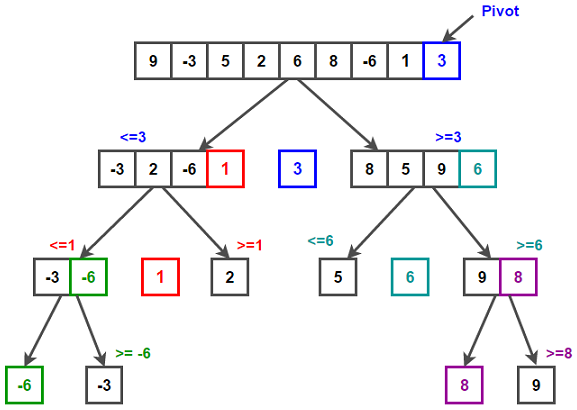
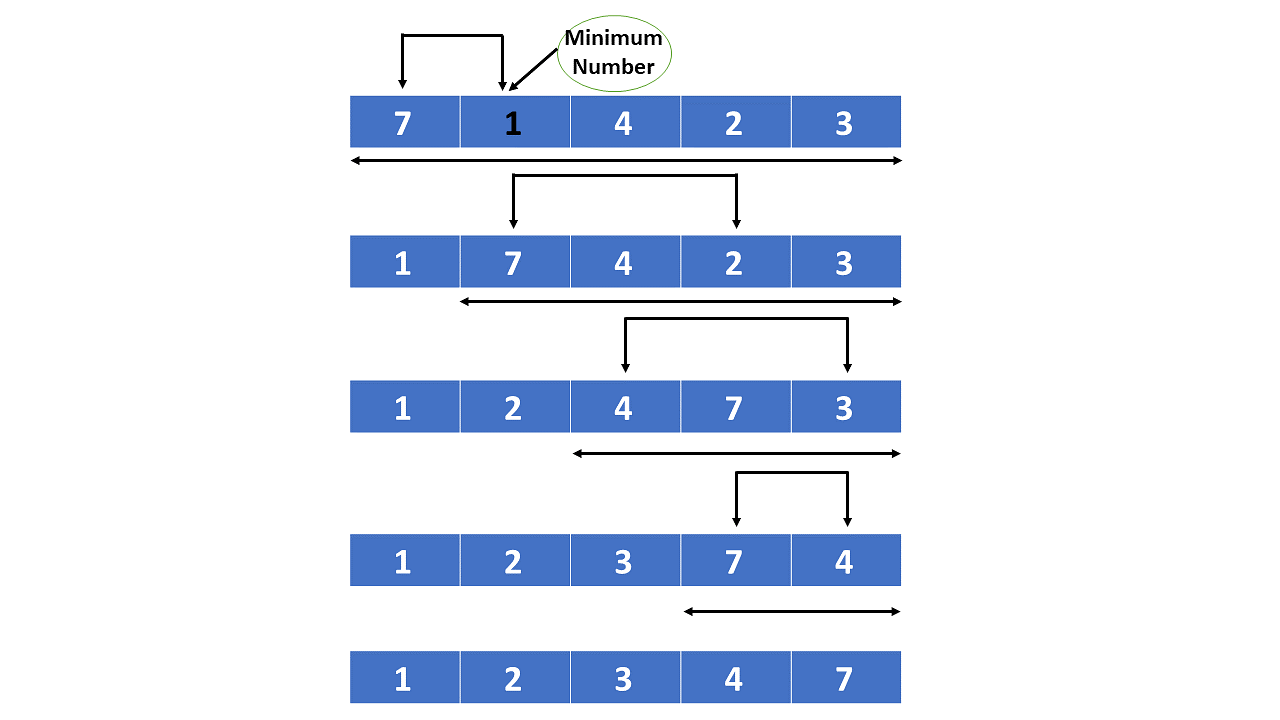
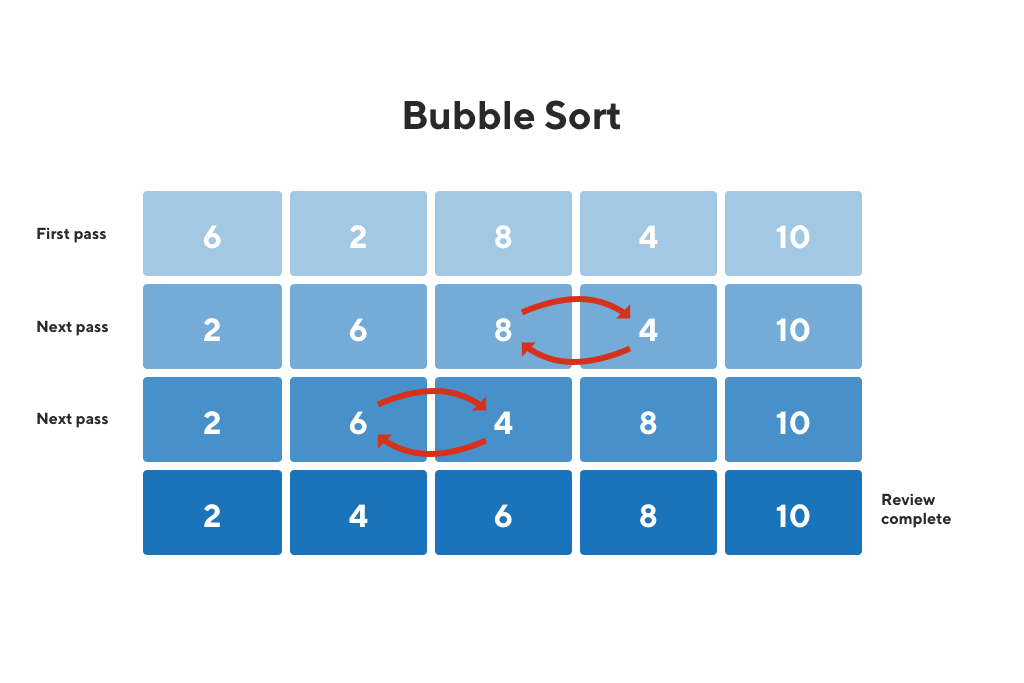
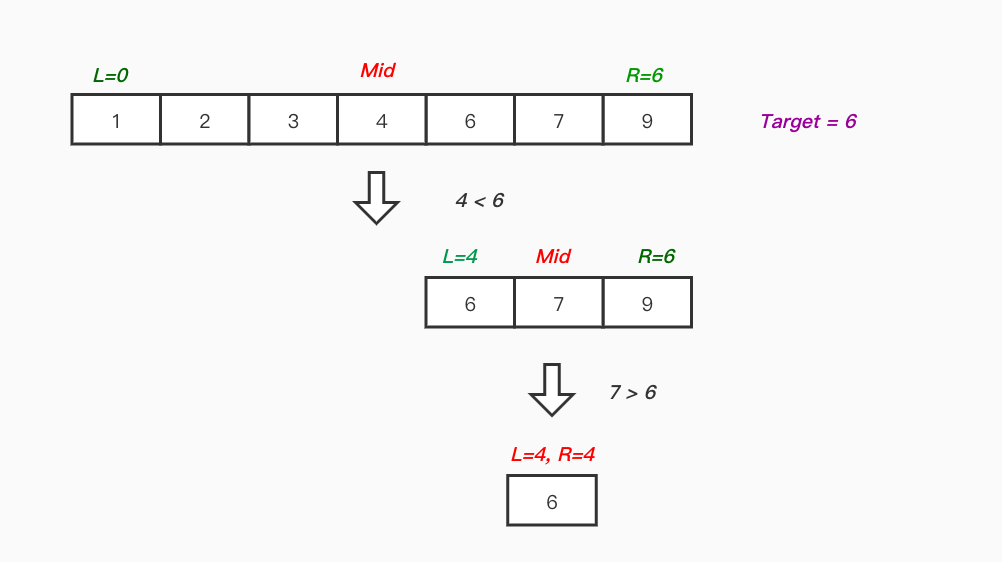
퀵 정렬(Quick Sort) 이해하기 퀵 정렬이란? 퀵 정렬은 분할 정복(Divide and Conquer) 기법을 활용한 효율적인 정렬 알고리즘입니다. 1959년 영국 컴퓨터 과학자 토니 호어(Tony Hoare)가 개발했습니다. 불안정 정렬에 속하며, 비교 기반의 정렬 알고리즘 중 하나입니다. 동작 원리 피벗(Pivot) 선택: 정렬할 리스트에서 하나의 원소를 피벗으로 선택합니다. 일반적으로 리스트의 첫 번째 또는 마지막 원소를 피벗으로 사용합니다. 파티셔닝(Partitioning): 피벗을 기준으로 리스트를 두 개의 부분 리스트로 분할합니다. 피벗보다 작은 값은 왼쪽 부분 리스트에, 큰 값은 오른쪽 부분 리스트에 배치합니다. 재귀 호출(Recursive Call): 분할된 두 개의 부분 리스트에 ..