필터링, 검출, 압축: CNN에서 슬라이딩 윈도우 사용법
- 컨볼루션 레이어로 필터링
- ReLU 활성화 함수로 검출
- 최대 풀링 레이어로 압축
컨볼루션과 풀링 작업은 모두 슬라이딩 윈도우를 사용해 수행됩니다. 컨볼루션에서는 이 윈도우가 kernel_size로 정의되고, 풀링에서는 pool_size로 정의됩니다.
컨볼루션과 풀링 레이어에 영향을 미치는 추가적인 두 가지 매개변수는 윈도우가 이동하는 거리인 strides와 입력 이미지의 가장자리에 대해 패딩을 적용할지 여부를 결정하는 padding입니다.
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Conv2D(filters=64,
kernel_size=3,
strides=1,
padding='same',
activation='relu'),
layers.MaxPool2D(pool_size=2,
strides=1,
padding='same')
# 추가적인 레이어
])스트라이드 (Stride)
슬라이딩 윈도우가 한 단계 이동할 때의 거리를 스트라이드라고 합니다. 이미지를 가로 방향으로 이동하는 거리와 세로 방향으로 이동하는 거리를 모두 지정해야 합니다. 아래 애니메이션은 strides=(2, 2)일 때, 윈도우가 2픽셀씩 이동하는 모습을 보여줍니다.

스트라이드가 1보다 큰 경우, 슬라이딩 윈도우는 입력의 일부 픽셀을 건너뛰게 됩니다.
컨볼루션 레이어에서는 일반적으로 strides=(1, 1)을 사용하여 높은 품질의 특징을 추출하려고 합니다. 반면 최대 풀링 레이어에서는 (2, 2) 또는 (3, 3)과 같이 스트라이드 값을 더 크게 설정하는 것이 일반적입니다.
스트라이드 값이 두 방향에서 동일한 경우, strides=2와 같이 단일 숫자로 설정할 수 있습니다.
패딩 (Padding)
슬라이딩 윈도우 계산을 수행할 때, 입력의 경계에서 어떻게 처리할지 결정해야 합니다. 윈도우가 입력 이미지 내에서만 머물게 하면 경계 픽셀들은 다른 픽셀들과 동일하게 처리되지 않을 수 있습니다.
컨볼루션에서 이 경계 값들을 어떻게 처리할지는 padding 매개변수로 결정됩니다. TensorFlow에서는 padding='same' 또는 padding='valid' 중 하나를 선택할 수 있습니다.
padding='valid'를 설정하면, 컨볼루션 윈도우는 입력 내부에만 머물게 됩니다. 그러나 이 경우 출력 크기가 줄어들며, 특히 큰 커널을 사용할 때 출력이 더 많이 줄어듭니다.

반면 padding='same'을 사용하면, 입력의 경계에 0으로 채워진 패딩을 추가하여 출력 크기를 입력과 동일하게 유지할 수 있습니다.
예제 - 슬라이딩 윈도우 탐구
슬라이딩 윈도우 매개변수의 효과를 더 잘 이해하기 위해, 저해상도 이미지에서 특징 추출을 관찰해 보겠습니다. 다음 코드는 간단한 원 이미지를 보여줍니다.
import tensorflow as tf
import matplotlib.pyplot as plt
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('image', cmap='magma')
image = circle([64, 64], val=1.0, r_shrink=3)
image = tf.reshape(image, [*image.shape, 1])
# Bottom sobel
kernel = tf.constant(
[[-1, -2, -1],
[0, 0, 0],
[1, 2, 1]],
)
show_kernel(kernel)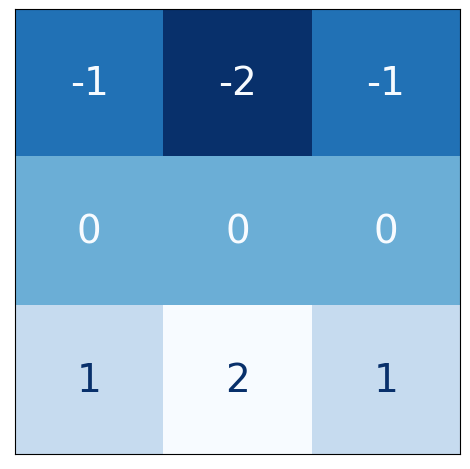
VGG 아키텍처는 단순합니다. 컨볼루션에는 스트라이드 1을, 최대 풀링에는 2×2 윈도우와 스트라이드 2를 사용합니다. 다음 코드는 모든 단계를 시각화해 줍니다.
show_extraction(
image, kernel,
# Window parameters
conv_stride=1,
pool_size=2,
pool_stride=2,
subplot_shape=(1, 4),
figsize=(14, 6),
)
수평선을 감지하도록 설계된 커널이 있으며, 결과적인 특징 맵에서 입력의 더 수평적인 부분이 가장 높은 활성화를 보이는 것을 알 수 있습니다.
컨볼루션의 스트라이드를 3으로 변경하면 어떻게 될까요?
show_extraction(
image, kernel,
# Window parameters
conv_stride=3,
pool_size=2,
pool_stride=2,
subplot_shape=(1, 4),
figsize=(14, 6),
)
이 경우 특징 추출의 품질이 떨어지는 것 같습니다. 입력 원의 두께는 1픽셀로 매우 세밀한데, 스트라이드 3을 사용한 컨볼루션은 너무 거칠어 좋은 특징 맵을 생성하지 못합니다.
일부 모델에서는 초기 레이어에서 스트라이드가 큰 컨볼루션을 사용할 수 있습니다. 이 경우 일반적으로 더 큰 커널을 함께 사용합니다. 예를 들어, ResNet50 모델은 첫 번째 레이어에서 7×7 커널과 스트라이드 2를 사용합니다. 이는 입력으로부터 너무 많은 정보를 희생하지 않고 대규모 특징을 더 빨리 생성할 수 있게 해줍니다.
수용 영역
뉴런의 모든 연결을 추적하면 결국 입력 이미지에 도달합니다. 특정 뉴런이 입력 이미지에서 정보를 받는 모든 픽셀 영역을 그 뉴런의 수용 영역이라고 합니다.
첫 번째 레이어가 3×3 커널을 사용하는 컨볼루션이라면, 그 레이어의 각 뉴런은 3×3 크기의 입력 픽셀 패치를 받습니다.
또 다른 컨볼루션 레이어를 3×3 커널로 추가하면 어떻게 될까요? 아래 그림에서 볼 수 있습니다:

가장 위에 있는 뉴런은 5×5 크기의 입력 픽셀 패치에 연결됩니다. 중간 레이어의 3×3 패치에 있는 각 뉴런은 3×3 입력 패치에 연결되며, 이들은 5×5 패치로 겹쳐집니다. 따라서 맨 위 뉴런의 수용 영역은 5×5가 됩니다.
1차원 컨볼루션 1D CNN
컨볼루션 네트워크는 2차원 이미지뿐만 아니라 1차원 시간 시계열과 3차원 비디오에도 유용합니다. 여기서는 "머신러닝"이라는 검색어의 인기 변화를 측정한 Google Trends의 시계열 데이터를 사용합니다.
import pandas as pd
# 시계열 데이터를 Pandas dataframe으로 로드
machinelearning = pd.read_csv(
'../input/computer-vision-resources/machinelearning.csv',
parse_dates=['Week'],
index_col='Week',
)
machinelearning.plot();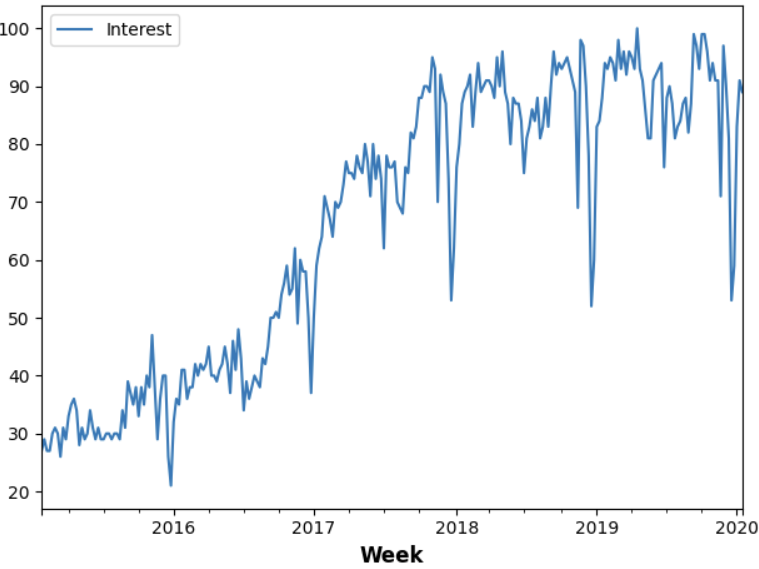
커널은 어떻게 될까요? 이미지는 2차원 배열이므로 커널도 2D 배열이었습니다. 그러나 시계열은
1차원이므로 커널도 1D 배열이 됩니다. 다음은 1차원 차분을 수행하는 커널입니다:
import tensorflow as tf
detrend = tf.constant([-1, 1], dtype=tf.float32)
average = tf.constant([0.2, 0.2, 0.2, 0.2, 0.2], dtype=tf.float32)
spencer = tf.constant([-3, -6, -5, 3, 21, 46, 67, 74, 67, 46, 32, 3, -5, -6, -3], dtype=tf.float32) / 320# UNCOMMENT ONE
kernel = detrend
#kernel = average
# kernel = spencer
# Reformat for TensorFlow
ts_data = machinelearning.to_numpy()
ts_data = tf.expand_dims(ts_data, axis=0)
ts_data = tf.cast(ts_data, dtype=tf.float32)
kern = tf.reshape(kernel, shape=(*kernel.shape, 1, 1))
ts_filter = tf.nn.conv1d(
input=ts_data,
filters=kern,
stride=1,
padding='VALID',
)
# Format as Pandas Series
machinelearning_filtered = pd.Series(tf.squeeze(ts_filter).numpy())
machinelearning_filtered.plot();
# UNCOMMENT ONE
#kernel = detrend
kernel = average
# kernel = spencer
# UNCOMMENT ONE
#kernel = detrend
#kernel = average
kernel = spencer
추세의 증가율을 단순히 시각화하는 방법을 보여주는 이 예제는 시계열 데이터에 대한 컨볼루션의 응용 가능성을 잘 나타냅니다. 이와 같은 컨볼루션 작업은 이미지 처리뿐만 아니라 다양한 유형의 데이터 처리에도 유용하게 적용될 수 있습니다.
'컴퓨터공학 > 인공지능' 카테고리의 다른 글
| Leetcode Introduction to Pandas 기본 문법 정리 (2) | 2024.10.10 |
|---|---|
| Custom Convnets 특수 제작 Convnet (79) | 2024.08.14 |
| Maximum Pooling 최대값 풀링 (79) | 2024.08.07 |
| 합성곱과 ReLU, Convolution (64) | 2024.08.06 |
| CNN - Convolution Neural Networks (85) | 2024.08.05 |